Das CCeH wird am 21. Mai 2019 einen Experten-Workshop zum Thema “Visualisierung in (digitalen) Editionen” an der Nordrhein-Westfälischen Akademie der Wissenschaften und der Künste in Düsseldorf ausrichten.
Die Teilnahme ist kostenfrei. Die Teilnehmerzahl ist allerdings begrenzt. Interessenten werden um schriftliche Anfrage an Herrn Nils Geißler gebeten: nils.geissler@uni-koeln.de
Programmübersicht
(Abstracts s.u.)
Einführung (9:30-10:00)
Patrick Sahle / Franz Fischer / Nils Geißler (Köln)
Literatur (10:00-11:00)
Jan Horstmann (Hamburg): Visualisierungsformen für quantitative und qualitative Methoden in der digitalen Literaturwissenschaft
Anna Busch (Potsdam): Eine digitale Autorenbibliothek und ihre Visualisierung als Erkenntnisinstrument. Am Beispiel Theodor Fontanes
Kaffeepause
Varianz & Genese (11:30-13:00)
Gabriel Viehhauser-Mery / Martin Baumann (Stuttgart): Visuelle, interaktive Analyse von Textvarianz am Beispiel der geplanten digitalen Edition von „Der Heiligen Leben, Redaktion“
Armin Hoenen (Frankfurt am Main): Das Stemma – eine printzeitalterliche Visualisierung in digitalen Editionen
Thorsten Vitt (Würzburg): Genesevisualisierungen in der Faustedition
Mittagspause (13:00-14:00)
Briefe (14:00-15:30)
Frederike Neuber (Berlin): Visualisierung als quantitative ‚Lesart‘ – Einige Experimente aus der Jean Paul-Briefedition
Claudia Bamberg / Bianca Müller (Marburg): Korrespondenzvisualisierung in der Literaturausstellung – am Beispiel der digitalen Edition August Wilhelm Schlegels
Jonas Müller-Laackman (Berlin): Explorative Visualisierungen für Korrespondenzmetadaten
Kaffeepause
Geschichte & Philosophie (16:00-17:00)
Britta Mischke / Marcello Perathoner (Köln): Mittelalterliche Handschriften in Raum und Zeit – eine interaktive Karte
Ruth Hagengruber / Julia Mühl / Stefanie Ertz / Niklas Olmes (Paderborn): Das Projekt Center for the History of Women Philosophers and Scientists als digitales Archiv: Datenpräsentation in Timeline, ECC und Manuskripte
Brigitte Grote / Lena-Luise Stahn / Sibylle Söring (Berlin): Visualisierungen mehrsprachiger Korpora am Beispiel von Hannah Arendt
Allgemeine Diskussion (17:00-17:30)
Praktische Infos
Veranstalter:
Koordinierungsstelle Digital Humanities der Nordrhein-Westfälischen Akademie der Wissenschaften am Cologne Center for eHumanities (CCeH) der Universität zu Köln
Organisation:
Prof. Dr. Patrick Sahle (Bergische Universität Wuppertal)
Prof. Dr. Franz Fischer (Università Ca‘ Foscari Venezia)
Nils Geißler (Universität zu Köln)
Kontakt:
nils.geissler@uni-koeln.de
Anfahrt:
http://www.awk.nrw.de/kontakt/
Beschreibung
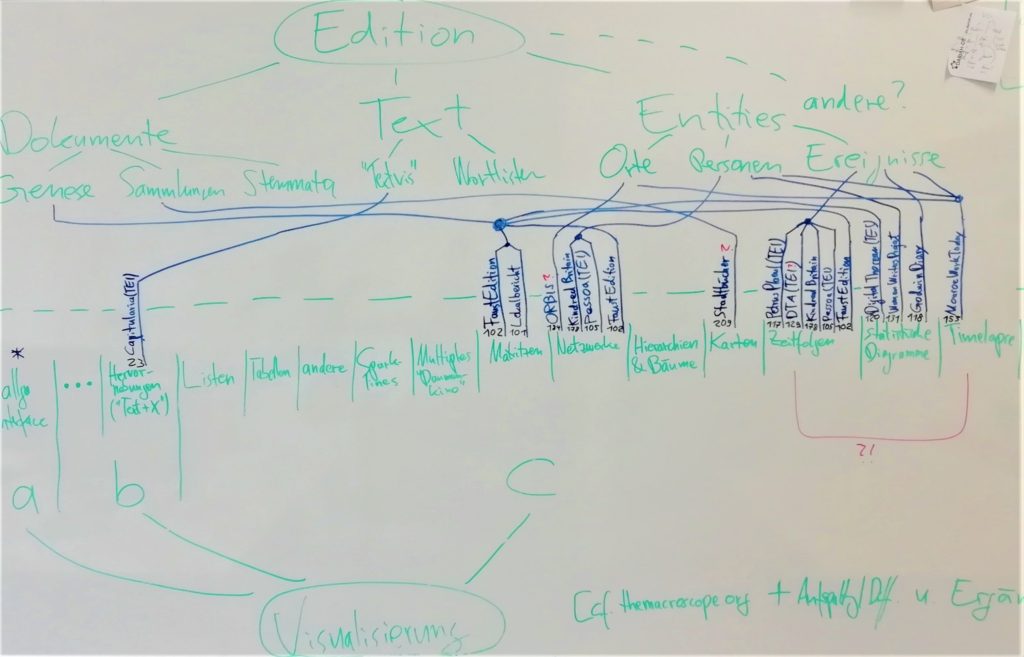
Digitale Editionen beruhen auf großen und komplexen Datenbeständen. Bei ihren digitalen Publikationsformen handelt es sich um visuelle Darstellungen, die sich unter verschiedenen Aspekten betrachten lassen: (1.) als Internet-Gesamtauftritt einschließlich der Inhaltsorganisation und Benutzerführung, (2.) als Präsentation von “Inhalten”, von Texten, Faksimiles oder Registern und (3.) als ergänzende Visualisierungen, die die inhaltlichen Komponenten und Strukturen sichtbar und damit verständlicher und besser nutzbar machen. In diesen dritten Bereich fallen Strukturvisualisierungen von Texten und Corpora, von Varianz und Genese sowie von Annotationen und Bezügen, graphische Darstellungen wie Timelines oder Karten und klassische Formen der Informationsvisualisierung wie statistische Diagramme und Netzwerke oder allgemeine schematische Übersichten für Phänomene und Strukturen in den Datenbeständen. Diese Visualisierungen können zugleich wieder filternde, explorative, interaktive oder weiterleitende (browsing-unterstützende) Funktionen haben und damit wieder den Bereich Inhaltsorganisation und Nutzerführung betreffen. Im Rahmen des Workshops „Visualisierung in (digitalen) Editionen“ sollen die bestehenden Ansätze vor allem im dritten Bereich, also der Informationsvisualisierung im engeren Sinne, gesichtet und diskutiert werden.
Abstracts
Jan Horstmann (Hamburg): Visualisierungsformen für quantitative und qualitative Methoden in der digitalen Literaturwissenschaft
Die Methoden der digitalen Literaturwissenschaft befassen sich mit sehr unterschiedlich großen Datengrundlagen. Im Bereich des distant reading werden Textdaten vor allem in ihrer Quantität visualisiert, auch wenn Verfahren wie Topic Modeling oder word2vec versuchen, auch automatisiert an die semantischen Tiefendimensionen von Texten heranzukommen. Die schiere Menge der Daten macht Visualisierungen jedoch unumgänglich, um einen Überblick und darauf aufbauend auch einen Einblick zu gewähren. Im Bereich des close reading können qualitative Daten (erstellt durch manuelle Annotation) visualisiert werden. Der systematische Einsatz von Visualisierungen in der literaturwissenschaftlichen Argumentation ist ein noch weitgehend unerschlossenes Feld, ein Gemeinplatz ist jedoch, dass hermeneutische Daten andere Visualisierungsformen erfordern als (vermeintlich) interpretationsfreie Daten (Drucker unterscheidet in diesem Sinne „data“ (die gegeben sind) von „capta“ (die genommen werden müssen)). Ich werde nach einem kurzen Überblick über das Methodenrepertoire der digitalen Literaturwissenschaft beispielhaft die Netzwerkanalyse (mit semantischen, gerichteten Netzwerken, die für die Visualisierung von Luhmanns Zettelkasten interessant sein könnten) sowie die Visualisierung von manuell erzeugten hermeneutischen Annotationen am Beispiel des Tools Stereoscope, das im Projekt 3DH für die visuelle Arbeit mit CATMA-Annotationen entwickelt wurde, besprechen.
Anna Busch (Potsdam): Eine digitale Autorenbibliothek und ihre Visualisierung als Erkenntnisinstrument. Am Beispiel Theodor Fontanes
In einem ersten Teil soll das Kooperationsprojekt zwischen dem Theodor-Fontane-Archiv Potsdam und dem UCLAB der Fachhochschule Potsdam zur Entwicklung eines Prototyps zur Visualisierung der Handbibliothek Theodor Fontanes vorgestellt werden (https://uclab.fh-potsdam.de/ff/). Daran schließen sich in einem zweiten Teil generellere Fragen an, die im Projektverlauf aufgetreten sind: Welche Arbeitsformen zwischen Archiv/Fachwissenschaft und Informatik/Digitaler Forschung sind für philologische Visualisierungsprojekte zielführend? Kann die einer Visualisierung zugrundeliegende Datenerfassung losgelöst von philologischer Deutung erfolgen? Welche Formen kann und muss eine Visualisierung annehmen, damit sie für Philologen „lesbar“ ist? Können digitale Interfaces eigene Erkenntnisinstrumente sein? Oder gibt es etwas, was durch die Visualisierung verloren geht – sind sie also in gewisser Hinsicht auch Erkenntnisverlustinstrumente?
Gabriel Viehhauser-Mery / Martin Baumann (Stuttgart): Visuelle, interaktive Analyse von Textvarianz am Beispiel der geplanten digitalen Edition von „Der Heiligen Leben, Redaktion“
„Der Heiligen Leben, Redaktion“ lautet der etwas sperrige Titel eines spätmittelalterlichen deutschen Legendars, also einer Sammlung von Lebensbeschreibungen christlicher Heiliger, die in den ersten Jahrzehnten des 15. Jahrhunderts im Nürnberger Raum entstanden ist. Die Sammlung stellt eine umfangreiche Bearbeitung und Erweiterung des weiter verbreiteten „Heiligen Leben“ dar, die in zwei Stufen erfolgt ist. An der Universität Stuttgart wird zurzeit die erste Edition dieser umfangreichen Textsammlung vorbereitet, bei der insbesondere der Erforschung der unterschiedlichen Bearbeitungstendenzen, die zwischen den einzelnen Stufen sichtbar werden, eine große Bedeutung zukommt.
Um diese Bearbeitungstendenzen und die Varianz, die zwischen den Texten besteht, besser überblicken zu können, werden zurzeit in interdisziplinärer Zusammenarbeit zwischen dem Institut für Literaturwissenschaft und dem Institut für Visualisierung und interaktive Systeme neue Möglichkeiten der Visualisierung von Textunterschieden erprobt. Im Vortrag möchten wir einen Ansatz vorstellen, der es erlaubt, für eine Auswahl von manuell und gemäß einer Reihe von Variantenkategorien annotierten Texten deren Varianzen makroperspektivisch darzustellen und miteinander zu vergleichen.
Armin Hoenen (Frankfurt am Main): Das Stemma – eine printzeitalterliche Visualisierung in digitalen Editionen
In der Editorik bestehen verschiedene Ansätze mit Variation rational umzugehen. Einer der bekanntesten ist dabei wohl die kritische Edition, welche meist einen Urtext (oder kritischen Text) durch vorherige Rekonstruktion der Kopiergeschichte der Textzeugen anhand von textuellen und metatextuellen Eigenschaften, wie z.B. gemeinsamer fehlender Zeilen, rekonstruiert. Das verbreiteteste Verfahren hierzu ist das sog. Lachmann’sche. Bei diesem Verfahren wird neben der Rekonstruktion verlorener anzestraler Textzeugen die Kopiergeschichte visualisiert undzwar als Graph, wobei Textzeugen Knoten und Kopierprozesse (oder -ketten) Kanten sind. Dieser Graph ist i.d.R. gerichtet und erlaubt so einen chronologischen Überblick über die Kopiergeschichte aller bekannten Textzeugen. In Printeditionen steht ein solches Stemma normalerweise am Ende der Einleitung. Mit Beginn des digitalen Zeitalters hat die Stemmatologie durch Adaptation von bio-informatischen und informatischen Ansätzen einen enormen Methodenzuwachs erlebt. Der Vortrag versucht daher, einen Überblick über sinnvolle Möglichkeiten, Stemmata für digitale Editionen zu produzieren und sie in ihnen zu platzieren zu geben.
Thorsten Vitt (Würzburg): Genesevisualisierungen in der Faustedition
Die Faustedition (faustedition.net) erschließt alle Handschriften und die zu Goethes Lebzeiten erschienenen relevanten Drucke des Faust. Der Beitrag stellt Visualisierungen aus dem Bereich der Textgenese vor sowie als experimentellsten Teil das Makrogenese-Lab, das Forschung zur Entstehungsgeschichte modelliert und visualisiert.
Frederike Neuber (Berlin): Visualisierung als quantitative ‚Lesart‘ – Einige Experimente aus der Jean Paul-Briefedition
Digitale wissenschaftliche Editionen zielen traditionell auf eine qualitative Tiefenerschließung sowie auf eine Visualisierung der Quellen bzw. Daten, die das einzelne Dokument fokussiert. Die Tiefenerschließung (z. B. Entitäten, Normdaten) kann man aber auch für quantitative Analysen fruchtbar machen. Eine adäquate bzw. den Benutzern zugängliche ‚Lesart‘ solcher Analysen ist die (Informations-)Visualisierung. Anhand eines Korpus von rund 5000 Briefen des Schriftstellers Jean Paul wird der Vortrag experimentelle Visualisierungen vorstellen, die neue Forschungsimpulse anregen. Ebenfalls thematisiert werden die dabei entstehenden konzeptionellen und technischen Herausforderungen, darunter ‚Fluch und Segen‘ großer Datensätze und die ‚Subjektivität‘ der Auswertung. Abschließend denkt der Vortrag an, wie Visualisierungen als quantitative ‚Lesarten‘ der Quellen digitale Editionen bereichern könnten.
Claudia Bamberg / Bianca Müller (Marburg): Korrespondenzvisualisierung in der Literaturausstellung – am Beispiel der digitalen Edition August Wilhelm Schlegels
Vorgestellt wird die interaktive Korrespondenzvisualisierung aus der Wanderausstellung ‚Aufbruch ins romantische Universum: August Wilhelm Schlegel‘ (Frankfurt, Bonn, Marburg, Jena), die auf zwei Touchscreens am Beginn der Schau zu sehen war. Sie veranschaulichte Schlegels weitgespanntes Briefnetzwerk: Die Besucher*innen konnten sich von der Briefnetzwerkansicht auf einer Europakarte bis hin zum einzelnen Brieffaksimile und dessen Transkription bewegen. Dafür sind Forschungsdaten aus der Digitalen Edition der Korrespondenz August Wilhelm Schlegels (www.august-wilhelm-schlegel.de) nachgenutzt und in FuD spezifisch modelliert worden. Der Visualisierung lag ein mit dem Trier Center for Digital Humanities entwickeltes, topographisches Design-Konzept zugrunde, das sich an den farblich markierten Ausstellungsstationen orientierte. Sie wurde zudem einer Testphase unter realen Nutzungsbedingungen unterzogen. Die Verwendung der Medienstation wurde während der Ausstellungsdauer auf beiden Rechnern zeitexakt protokolliert.
Jonas Müller-Laackman (Berlin): Explorative Visualisierungen für Korrespondenzmetadaten
Der Webservice correspSearch aggregiert Korrespondenzmetadaten und stellt sie zur Recherche und Abfrage via API zur Verfügung. In Zukunft sollen die Recherchezugänge um Visualisierungen ergänzt werden, die eine leichte Exploration des großen Datenbestandes (derzeit über 50.000 Briefe) möglich machen. Der Beitrag stellt erste Überlegungen und Tests hierzu vor.
Britta Mischke / Marcello Perathoner (Köln): Mittelalterliche Handschriften in Raum und Zeit – eine interaktive Karte
Das Capitularia-Projekt erarbeitet eine Hybridedition der fränkischen Herrschererlasse (‚Kapitularien‘), die eine kritische Printedition mit der Erschließung aller handschriftlichen Textzeugen in Form einer digitalen Edition verbindet. Die auf der Projekthomepage gesammelten Informationen zu den ca. 300 Überlieferungsträgern mit Kapitulariensammlungen sollen zukünftig durch Visualisierungen anschaulich präsentiert werden. Im Workshop stellen wir einen ersten Entwurf für eine interaktive Karte mit den Entstehungsorten der Handschriften vor. Über verschiedene Filteroptionen können Abfragen zu Entstehungsorten, –daten und Inhalten der jeweiligen Handschriften miteinander kombiniert und auf der Karte dargestellt werden. Neben einer übersichtlichen Präsentation der reichen Überlieferung soll damit auch die Nutzung der Daten für Forschungsfragen angeregt werden.
Ruth Hagengruber / Julia Mühl / Stefanie Ertz / Niklas Olmes (Paderborn): Das Projekt Center for the History of Women Philosophers and Scientists als digitales Archiv: Datenpräsentation in Timeline, ECC und Manuskripte
Das Center for the History of Women Philosophers and Scientists als digitales Archiv zu Schriften von Philosophinnen hat es sich zum Ziel gemacht, Texte von Philosophinnen, die zur Verfügung stehen, zu digitalisieren, zu sammeln und zu katalogisieren. Zu diesem Zweck wurde im Rahmen des Projekts ein Directory, eine Timeline und eine Enzyklopädie (ECC- Encyclopedia of Concise Concepts by Women Philosophers) entwickelt. In unserem Vortrag werden wir die verschiedenen Projekte und Darstellungsweisen der Daten präsentieren und auf die Möglichkeiten und Schwierigkeiten der Verknüpfung von vorhandenem Datenmaterial und der Visualisierung hinweisen.
Brigitte Grote / Lena-Luise Stahn / Sibylle Söring (Berlin) Visualisierungen mehrsprachiger Korpora am Beispiel von Hannah Arendt
Hannah Arendt gilt als eine der bedeutendsten politischen Denkerinnen des 20. Jahrhunderts, die nicht zuletzt aufgrund ihres in zwei Sprachen (Englisch, Deutsch) verfassten Werkes eine große internationale Reichweite erlangt hat. Diese Zweisprachigkeit ihrer Texte und die damit eröffneten unterschiedlichen Denk-Welten ein und derselben Autorin stellen eine Besonderheit dieses Textkorpus‘ dar: Während bereits die zahlreichen Varianten und Fassungen einzelner Texte Ausdruck eines intensiven Überarbeitungsprozesses sind, verfasste Arendt ihre Ideen („Denk-Gebäude“) im jeweiligen Sprachraum zudem genuin neu, oft auch ganz anders entwickelt.
Die „klassische“ Präsentation des Textkorpus‘ des Editionsvorhabens „Hannah Arendt. Kritische Gesamtausgabe und Hybridedition“ (Projektwebseite: http://www.arendteditionprojekt.de/ ), realisiert durch synoptische Ansichten der editorischen Umschriften (diplomatische und Lesefassung, daneben Faksimile und TEI/XML des Dokuments), die auf einzelne Texte ausgerichtet ist, kann dieser sprachlich begründeten Verschiedenheit nicht gerecht, Arendts Denkprozess so nur bedingt herausgearbeitet werden. Vielmehr sind Visualisierungen der Gemeinsamkeiten und Unterschiede zwischen ein- und mehrsprachigen Textvarianten und Textfassungen sowohl auf Ebene der Textstruktur als auch der Syntax und Lexik usw. erforderlich. Im Vortrag wird die Problematik anhand des Arendt-Korpus illustriert, Bedarfe an die Visualisierung formuliert und erste Lösungsideen (für monolinguale Texte) unter Verwendung von Verfahren des Text Alignments (z.B. LERA (Locate, Explore, Retrace and Apprehend complex text variants, lera.uzi.uni-halle.de) aufgezeigt.