
2019 kommt es Schlag auf Schlag. Nur einen Monat nach dem erfolgreichen Launch des Niklas-Luhmann-Archivs folgt schon der nächste Grund zu feiern.
Im Rahmen des Workshops “Editions- und Forschungsplattformen zum 18. Jahrhundert” wurde am 8. Mai 2019 in Bern feierlich die neue Plattform hallerNet vorgestellt und eröffnet.
Im Auftrag der Albrecht von Haller-Stiftung wurde das Projekt von 2016 bis 2019 in enger Zusammenarbeit des CCeH mit der Universität Bern realisiert. Die schon seit den 90er Jahren aufgebauten umfangreichen und komplexen Datenbanken zum Leben und Werk, vor allem aber auch zum Korrespondenznetzwerk des Schweizer Universalgelehrten Albrecht von Haller (1708-1777) wurden zunächst in ein TEI-XML-Format transformiert. 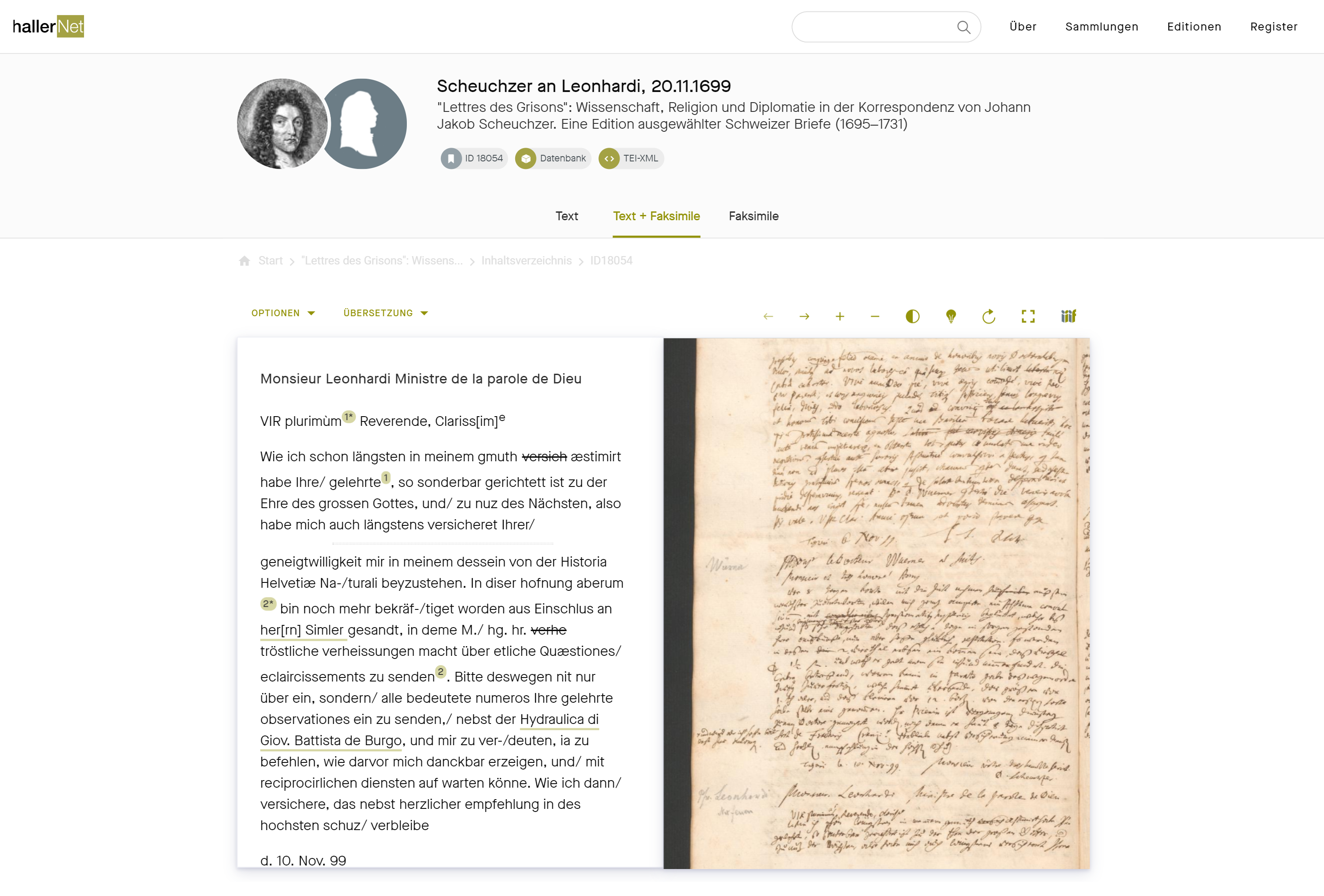 Darauf aufbauend entstand eine Plattform, die aktuell insgesamt Metadaten zu rund 48’000 Publikationen, 25’000 Personen, 17’000 Briefen, 3’000 Orten, 850 Institutionen und demnächst 2’900 Pflanzenarten und 1’000 Versammlungen sowohl im Kontext personen- und institutionszentrierter Sammlungen präsentiert und systematisch mit digitalen Editionen verknüpft. Darüber hinaus wird die Plattform auch als Grundlage für weitere Editions- und Forschungsprojekte zum Werk Hallers dienen, zunächst im SNF-Projekt “Online-Edition der Rezensionen und Briefe Albrecht von Hallers Expertise und Kommunikation in der entstehenden Scientific community“ (2018-2023).
Darauf aufbauend entstand eine Plattform, die aktuell insgesamt Metadaten zu rund 48’000 Publikationen, 25’000 Personen, 17’000 Briefen, 3’000 Orten, 850 Institutionen und demnächst 2’900 Pflanzenarten und 1’000 Versammlungen sowohl im Kontext personen- und institutionszentrierter Sammlungen präsentiert und systematisch mit digitalen Editionen verknüpft. Darüber hinaus wird die Plattform auch als Grundlage für weitere Editions- und Forschungsprojekte zum Werk Hallers dienen, zunächst im SNF-Projekt “Online-Edition der Rezensionen und Briefe Albrecht von Hallers Expertise und Kommunikation in der entstehenden Scientific community“ (2018-2023).
Das Haller-Team am CCeH
Projektleitung
- Patrick Sahle
- Peter Dängeli
Datenmodellierung und -transformation
- Antonio Rojas Castro
- Peter Dängeli
- Nils Geißler (Bildmetadaten)
Arbeitsumgebung (oXygen Author mode)
- Andreas Mertgens
Entwicklung Backend
- Peter Dängeli
Entwicklung Frontend
- Arjan Dhupia (Leitung)
- Jan Bigalke
- Sebastian Zimmer
Beratung
- Franz Fischer (Konzept und Datenmodell)
- Bernhard Strecker (Anwendungsarchitektur)