Blumtritt, Jonathan, Johan Frid, Jens Larsson, Martin Matthiesen, und Felix Rau. „Challenges and Developments in Preserving and Publishing of Large Audio/Video Data“. In Research Data and Humanities – RDHum 2019. Oulu, 2019.
Blumtritt, Jonathan, und Patrick Helling. „Umfragen und Analyse von Beratungsgesprächen als strategische Wegweiser“. Bausteine Forschungsdatenmanagement, Nr. 2 (2019): 96–103. https://doi.org/10.17192/bfdm.2019.2.8165.
———. „Umfragen und Analyse von Beratungsgesprächen als strategische Wegweiser in den Geisteswissenschaften“. In DINI/nestor-Workshop „Bedarfserhebungen – Grundlage für passgenaue Infrastrukturen?“, 2:96–103. Duisburg, 2019. https://doi.org/10.17192/bfdm.2019.2.8165.
Blumtritt, Jonathan, Patrick Helling, und Ulrike Wuttke. „Wie es Euch gefällt? Perspektiven wissenschaftsgeleiteter Organisationsformen des Datenmanagements für die Geisteswissenschaften“. In DHd 2019. Digital Humanities: multimedial & multimodal. Konferenzabstracts, 74–77. Frankfurt am Main, 2019. https://doi.org/10.5281/zenodo.2596095.
Blumtritt, Jonathan, und Claes Neuefeind. „Forschungsdaten oder Forschungssoftware? Digitale Editionen als Herausforderung für Forschungsdateninfrastrukturen“. Gehalten auf der DH-NRW Jour Fixe, Essen, 8. Mai 2019.
Blumtritt, Jonathan, und Felix Rau. „Metadaten im Zeitalter von Google Dataset Search“. In DHd 2019. Digital Humanities: multimedial & multimodal. Konferenzabstracts, 173–75. Frankfurt am Main, 2019. https://doi.org/10.5281/zenodo.2596095.
Bornus, Pia, Elisabeth Reuhl, und Gwenlyn Tiedemann. „Online-Ressourcen, semantische Erschließung und Virtual Reality. Drei Perspektiven zur Provenienzforschung an der Instrumentensammlung der Kölner Musikwissenschaft“, 2019.
Boscani Leoni, S., Peter Dängeli, Christian Forney, und Martin Stuber. „Editions- und Forschungsplattformen zum 18. Jahrhundert. Workshop zur Eröffnung von hallerNet“. 5. August 2019. https://files.hallernet.org/public-www/presentations/hallerNet-Eroeffnung-I/#1.
Dängeli, Peter. „Die Nachhaltigkeitsproblematik digitaler Editionen – Workshopbericht“. DHd-Blog (blog), 2. September 2019. https://dhd-blog.org/?p=11033.
Dängeli, Peter, und Christian Forney. „Referencing annotations as a core concept of the hallerNet edition and research platform“, 2019. https://zenodo.org/record/3446232.
Dängeli, Peter, Martin Stuber, und Christian Forney. „Vom Stellenkommentar zum Netzwerk und zurück: große Quellenkorpora und tief erschlossene Strukturdaten auf hallerNet“, 2019. https://files.hallernet.org/public-www/presentations/dhd2019/.
Dängeli, Peter, Magnus Wieland, und Simon Zumsteg. „Digitale Edition von Hermann Burgers Lokalbericht“. In Textgenese in der digitalen Edition, herausgegeben von A. Bosse und W. Fanta, 265–80. Berlin / Boston: De Gruyter, 2019.
Dängeli, Peter, Dieter Hagedorn, und Klaus Maresch. „cceh/papyri-wl-data: v23: 23. Fassung vom 25. Juli 2019“. Zenodo, 25. Juli 2019. https://doi.org/10.5281/zenodo.3359670.
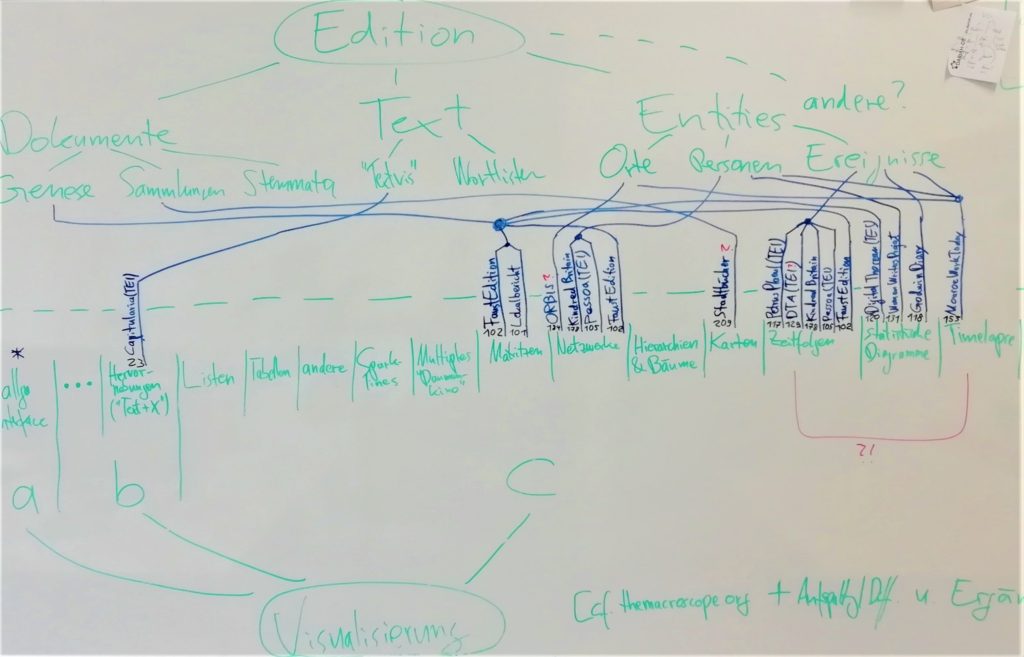
Geißler, Nils. „Visualisierung in (digitalen) Editionen – Rekapitulation“. Gehalten auf der Auffindbarkeit und Referenzierbarkeit von Forschungsdaten (Workshop, 11.-12.06.2019, ADWHH), Hamburg, 6. November 2019.
Gengnagel, Tessa. „Digital Scholarly Editions Beyond Text: Modelling Medieval Picture Programmes and Modern Motion Pictures“. In Symposium der Volkswagenstiftung: Positioning the Humanities in the 2020s. Schloss Herrenhausen, 2019.
Gengnagel, Tessa, Roman Bleier, Franz Fischer, Patrick Sahle, und Andrea Worm. „Text – Graph – Image: Towards a Digital Edition of Peter of Poitiers’ Compendium historiae“. In TEI-Konferenz: What is Text, Really? TEI and Beyond, 2019.
Kiss, Börge, Daniel Kölligan, Francisco Mondaca, Claes Neuefeind, Uta Reinöhl und Patrick Sahle. „It Takes a Village: Co-developing VedaWeb, a Digital Research Platform for Old Indo-Aryan Texts“. In TwinTalks@DHN 2019 – Understanding Collaboration in Digital Humanities, herausgegeben von Steven Krauwer und Darja Fišer, 2019. http://ceur-ws.org/Vol-2365/05-TwinTalks-DHN2019_paper_5.pdf.
Mathiak, Brigitte, Katja Metzmacher, Patrick Helling, und Jonathan Blumtritt. „The Role Of Data Archives In The Humanities At The University Of Cologne“. In DH2019 Book of Abstracts. Utrecht, 2019.
Mertgens, Andreas, Nora Probst, und Enes Türkoğlu. „(Re-)Collecting Theatre History: Wissensdinge, Biographien, Wirkungsräume“. Gehalten auf der Digital Humanities Kolloquium Köln, Köln, 18. April 2019.
Mertgens, Andreas, und Patrick Sahle. „The Harold Garfinkel Papers: On Digital Archives and Visual Interfaces“. Gehalten auf der SFB 1187 Jahrestagung – Data Practices: Recorded, Provoked, Invented, Siegen, 25. Oktober 2019.
Metzmacher, Katja, Patrick Helling, Jonathan Blumtritt, und Brigitte Mathiak. „Umfrage zu Forschungsdaten in den Geistes- und Humanwissenschaften an der Universität zu Köln“. In DHd 2019. Digital Humanities: multimedial & multimodal. Konferenzabstracts, 350–52. Frankfurt am Main, 2019. https://doi.org/10.5281/zenodo.2596095.
Mondaca, Francisco. „Más Allá de la Digitalización: el Rol del Acceso a Información Lexicográfica en Internet“. Instituto de Literatura y Ciencias del Lenguaje, Pontificia Universidad Católica de Chile, 4. August 2019. http://www.tecling.com/files/20190408_mondaca_ilcl.pdf.
Mondaca, Francisco, und Börge Kiss. „Introducing the VedaWeb APIs“. Gehalten auf der Workshop „Texts and APIs: The Distributed Text Services“, 15 July 2019, Hamburg, Hamburg, 15. Juli 2019. https://doi.org/10.5281/zenodo.3334863.
Mondaca, Francisco, Felix Rau, Claes Neuefeind, Börge Kiss, D. Kölligan, U. Reinöhl, und Patrick Sahle. „C-SALT APIs – Connecting and Exposing Heterogeneous Language Resources“. In: Book of Abstracts of the Digital Humanities Conference 2019 (DH2019). Utrecht, Netherlands. 09.–12.7.2019. https://dev.clariah.nl/files/dh2019/boa/0401.html.
Mondaca, Francisco, Philip Schildkamp, und Felix Rau. „Introducing Kosh, a Framework for Creating and Maintaining APIs for Lexical Data“. In Electronic Lexicography in the 21st Century. Proceedings of the eLex 2019 Conference, Sintra, Portugal, 907–21. Brno: Lexical Computing CZ, 2019. https://elex.link/elex2019/wp-content/uploads/2019/09/eLex_2019_51.pdf.
Mondaca, Francisco, Philip Schildkamp, Felix Rau, und Jan Bigalke. „Introducing an Open, Dynamic and Efficient Lexical Data Access for TEI-Encoded Dictionaries on the Internet“. In TEI 2019. What is text, really? TEI and beyond, 2019. https://gams.uni-graz.at/o:tei2019.158/sdef:TEI/get?context=context:tei2019.papers.
Neuefeind, C.: “Muster und Bedeutung. Bedeutungskonstitution als kontextuelle Aktivierung im Vektorraum.” Köln: MAP (Modern Academic Publishing). DOI: https://doi.org/10.16994/bam. ISBN: 978-3-946198-40-6.
Neuefeind, C., Schildkamp, P., Mathiak, B., Marčić, A., Hentschel, F., Harzenetter, L., Breitenbücher, U., Barzen, J., Leymann, F.: “Sustaining the Musical Competitions Database: a TOSCA-based Approach to Application Preservation in the Digital Humanities”. In: Book of Abstracts of the Digital Humanities Conference 2019 (DH2019). Utrecht, Netherlands. 09.–12.7.2019.
Neuefeind, C., Schildkamp, P., Mathiak, B., Harzenetter, L., Breitenbücher, U., Barzen, J., Leymann, F.: “Technologienutzung im Kontext Digitaler Editionen – eine Landschaftsvermessung”. In: Book of Abstracts der 6. Jahrestagung der Digital Humanities im deutschsprachigen Raum (DHd 2019), Mainz/Frankfurt a.M. 25.–29.3.2019, S. 219–222.
Richter M., Hermes J., Neuefeind C.: “Aspectual Classifications: Use of Raters’ Associations and Co-occurrences of Verbs for Aspectual Classification in
German”. In: van den Herik J., Rocha A. (eds) Agents and Artificial Intelligence. ICAART 2018. Lecture Notes in Computer Science, vol 11352. Springer, Cham. DOI: https://doi.org/10.1007/978-3-030-05453-3_22
Rojas Castro, Antonio. „Modeling FRBR entities and their relationships with TEI“, 2019. https://zenodo.org/record/3446218.
Sahle, Patrick, Franz Fischer, und Nils Geißler. „Visualisierung in (digitalen) Editionen“. Gehalten auf der Visualisierung in (digitalen) Editionen, Düsseldorf, 21. Mai 2019.
Sahle, Patrick, und Andreas Mertgens. „Nachlässe: Erschließung, Digitalisierung, Präsentation, Nutzung. Übung an der Fakultät für Geistes- und Kulturwissenschaften“. Lehre: Übung, 2020 2019. Schmidt, Thomas, Jonathan Blumtritt, Hanna Hedeland, Jan Gorisch, Felix Rau, und Kai Wörner. „Qualitätsstandards und Interdisziplinarität in der Kuration audiovisueller (Sprach-)Daten“. In DHd 2019. Digital Humanities: multimedial & multimodal. Konferenzabstracts, 41–44. Frankfurt am Main, 2019. https://doi.org/10.5281/zenodo.2596095.
Schaeben, Marcel, und Randa El-Khatib. „Mapping the Moralized Geography of ‚Paradise Lost‘: Prototypenbildung am Beispiel einer geo-kritischen Erschließung von Miltons Werk“. In DHd 2019. Digital Humanities: multimedial & multimodal. Konferenzabstracts, herausgegeben von Christoph Schöch, 317–19, 2019. https://zenodo.org/record/2596095/files/2019_DHd_BookOfAbstracts_web.pdf.
Schubert, Zoe, Øyvind Eide, Enes Türkoğlu, und Jan Wieners. „The intangibility of Tangible Objects. Re-telling Artefact Stories through Annotations and 3D Replica“. In ICOM KYOTO 2019 – Museums as Cultural Hubs: The Future of Tradition. Kyoto, 2019.
Seyfeddinipur, Mandana, Felix Ameka, Lissant Bolton, Jonathan Blumtritt, Brian Carpenter, Hilaria Cruz, Sebastian Drude, u. a. „Public Access to Research Data in Language Documentation: Challenges and Possible Strategies“. Language Documentation & Conservation 13 (2019): 545–63.
———. „Public Access to Research Data in Language Documentation: Challenges and Possible Strategies“. Language Documentation & Conservation 13 (2019): 545–63.
Türkoğlu, Enes. „Die DHd2019 als Treffen der EntdeckerInnen“. DHd-Blog (blog), 23. April 2019. https://dhd-blog.org/?p=11622.
———. „Putting back into context: an attempt to understand theater-historical objects through digitization“. Lehre: Blockseminar, 11. Mai 2019.
———. „Vom Digitalisat zum Kontextualisat – einige Gedanken zu digitalen Objekten“. In DHd 2019 Digital Humanities: multimedial & multimodal, Frankfurt am Main: Konferenzabstracts, 232–34, 2019. https://doi.org/10.5281/zenodo.2596095.
———. „Vom Digitalisat zum Kontextualisat – einige Gedanken zu digitalen Objekten“. Gehalten auf der Das prometheus-Bildarchiv: Daten^7 – Digitales BilderLeben, Köln, 10. Januar 2019. https://prometheus-bildarchiv.de/de/tagung2019/index.
———. „Vom Digitalisat zum Kontextualisat – einige Gedanken zu digitalen Objekten“. Gehalten auf der BBAW DH-Kolloquium, Berlin, 5. März 2019. https://dhd-blog.org/?p=11570.
Türkoglu, Enes, und Nora Porbst. „Magische ›Wiederbelebung‹? Zur historischen und gegenwärtigen Reanimation von Spielfiguren und Masken“. In 100 Jahre Theaterwissenschaftliche Sammlung Köln. Dokumente, Pläne, Traumreste, herausgegeben von Peter W. Marx. Berlin: Alexander-Verlag, 2019.